
میواتی ادبی ورثے کی ڈیجیٹل بحالی اور لسانی تدوین

حکیم المیوات قاری محمد یونس شاہد میو
میواتی ادب کا پس منظر اور سماجی لسانیاتی اہمیت
میواتی ادب محض ایک علاقائی زبان کے اظہار کا نام نہیں ہے، بلکہ یہ شمالی ہندوستان کے علاقہ میوات اور تقسیمِ ہند کے بعد پاکستان کے مختلف حصوں میں آباد میو برادری کی صدیوں پر محیط اجتماعی دانش، تاریخی شعور اور ثقافتی بقا کا امین ہے۔ لسانیاتی اعتبار سے میواتی زبان ہند-آریائی خاندان سے تعلق رکھتی ہے اور یہ ہریانوی، برج بھاشا، راجستھانی اور اردو کے درمیان ایک قدرتی لسانی پُل کا کام کرتی ہے 1۔ اس زبان کی جڑیں اساطیری دور تک پھیلی ہوئی ہیں، جہاں میوات کے خطے کا تذکرہ مہا بھارت کے زمانے سے ملتا ہے 4۔ میو برادری، جو کہ بنیادی طور پر راجپوت الاصل ہے، صوفیائے کرام کی تبلیغ کے نتیجے میں اسلام کے دائرے میں داخل ہوئی، جس نے ان کے ادب میں ایک منفرد امتزاج پیدا کیا جہاں اسلامی اقدار اور مقامی ہندوستانی روایات ایک دوسرے کے ساتھ پیوست نظر آتی ہیں 2۔
تاریخی طور پر میوات کبھی بھی ایک باقاعدہ انتظامی اکائی نہیں رہا، لیکن اس کے باوجود اس خطے نے اپنی لسانی اور ثقافتی شناخت کو نہایت مضبوطی سے برقرار رکھا ہے۔ موجودہ جغرافیائی تناظر میں یہ علاقہ ہندوستان کے تین صوبوں یعنی ہریانہ (نوح، گڑگاؤں)، راجستھان (الور، بھرت پور) اور اتر پردیش کے کچھ حصوں پر مشتمل ہے 2۔ 1947 کی تقسیم نے اس لسانی گروہ کو دو حصوں میں بانٹ دیا، جس کے نتیجے میں میواتی ادب کی بقا اور تحفظ کی کوششیں بھی جغرافیائی طور پر منقسم ہو گئیں 2۔ ہندوستان میں موجود میواتی ورثہ زیادہ تر زبانی روایات اور صوتی خزانوں پر مشتمل ہے، جبکہ پاکستان میں اس زبان کو تحریری شکل دینے اور اسے تعلیمی و انتظامی سطح پر متعارف کروانے کے لیے ایک منظم تحریک جنم لے چکی ہے 2۔
میواتی ادب کی اہمیت اس کی دوہری نوعیت میں پوشیدہ ہے؛ ایک طرف یہ گہری زبانی روایات (Oral Traditions) میں پیوست ہے تو دوسری طرف یہ جدید تحریری شکل اختیار کرنے کے عبوری مراحل سے گزر رہا ہے۔ اس کی تدوین محض ایک لسانی ضرورت نہیں بلکہ برصغیر کے وسیع تر ادبی منظرنامے کو سمجھنے کے لیے ناگزیر ہے، کیونکہ میواتی لوک ادب ان تاریخی واقعات اور سماجی تبدیلیوں کا عکاس ہے جنہیں سرکاری تاریخ میں جگہ نہیں مل سکی۔
| میواتی زبان کے لسانی پہلو | تفصیل و اثرات |
| لسانی خاندان | ہند-آریائی (Indo-Aryan) |
| ہمسایہ زبانیں | ہریانوی، برج بھاشا، راجستھانی، پنجابی، اردو 1 |
| رسم الخط | اردو (نستعلیق)، دیوناگری 2 |
| بنیادی اصناف | لوک گیت، رزمیہ داستانیں، کہاوتیں، ضرب الامثال |
| جغرافیائی پھیلاؤ | ہندوستان (راجستھان، ہریانہ)، پاکستان (پنجاب، سندھ) 2 |
زبانی روایات: میواتی ادب کا اصل سرمایہ
میواتی ادب کا سب سے بڑا اور قیمتی ذخیرہ اس کی زبانی روایات ہیں جو نسل در نسل سینہ بہ سینہ منتقل ہوتی رہی ہیں۔ یہ روایات میو برادری کی روزمرہ زندگی، سماجی اقدار اور تاریخی مزاحمت کا آئینہ دار ہیں۔ ان زبانی روایات کو محفوظ رکھنے میں ‘جوگیوں’ اور ‘مراسیوں’ جیسے روایتی فنکاروں کا کردار مرکزی رہا ہے، جو اس ادبی ورثے کے متحرک آرکائیوز سمجھے جاتے ہیں 3۔
پنڈون کا کڑا: ایک علاقائی رزمیہ
میواتی لوک ادب میں سب سے نمایاں مقام ‘پنڈون کا کڑا’ (Pandoon ka Kada) کو حاصل ہے، جو کہ مہا بھارت کا ایک میواتی ورژن ہے۔ یہ رزمیہ داستان ڈھائی ہزار سے زائد دوہوں پر مشتمل ہے اور اسے روایتی طور پر میواتی جوگی سارنگی اور دیگر سازوں کے ساتھ پیش کرتے ہیں 3۔ پنڈون کا کڑا محض ایک کہانی نہیں بلکہ میواتی شناخت کا ایک اہم ستون ہے، کیونکہ اس میں مہا بھارت کے کرداروں کو میوات کے مخصوص جغرافیائی اور سماجی سیاق و سباق میں ڈھالا گیا ہے 3۔ اس کے علاوہ ‘ڈھولا مارو ری بات’ جیسے قصے بھی برادری کے اساطیری ہیروز کے ساتھ ایک گہرا جذباتی تعلق قائم کرتے ہیں۔
لوک گیت اور سماجی زندگی
میواتی لوک گیت سماجی زندگی کے ہر پہلو کا احاطہ کرتے ہیں۔ زراعت اس خطے کی معیشت کا محور رہی ہے، لہٰذا فصلوں کی کٹائی، بارش اور موسموں سے متعلق گیتوں کی ایک وسیع کہکشاں موجود ہے 1۔ اسی طرح عورتوں کے احساسات، امیدیں اور مشکلات ‘پنی ہاری’ (Panihari) جیسے گیتوں میں نمایاں ہیں، جو کنویں سے پانی بھرنے والی عورتوں کی زندگی کی عکاسی کرتے ہیں 1۔ خوشی اور غمی کی رسومات کے لیے مخصوص گیت جیسے ‘رتی جگا’ (Ratijaga) اور ‘ڈانگڑی رات’ (Dangari-rat) بھی اس ادب کا حصہ ہیں 8۔
کہاوتیں اور ضرب الامثال
میواتی کہاوتیں صدیوں کی حکمت اور تجربے کا نچوڑ ہیں۔ یہ کہاوتیں نہ صرف اخلاقیات اور عملی زندگی کے اصول بیان کرتی ہیں بلکہ ان سے میواتی معاشرت کے پدر شاہی ڈھانچے اور زرعی حکمتِ عملیوں کا بھی بخوبی اندازہ لگایا جا سکتا ہے 1۔ ان مختصر جملوں میں سماجی رویوں کا جو گہرا تجزیہ ملتا ہے، وہ میواتی ذہن سازی کو سمجھنے کے لیے ایک بہترین علمی ذریعہ فراہم کرتا ہے۔
میواتی ادب کی تدوین کے کثیر جہتی چیلنجز
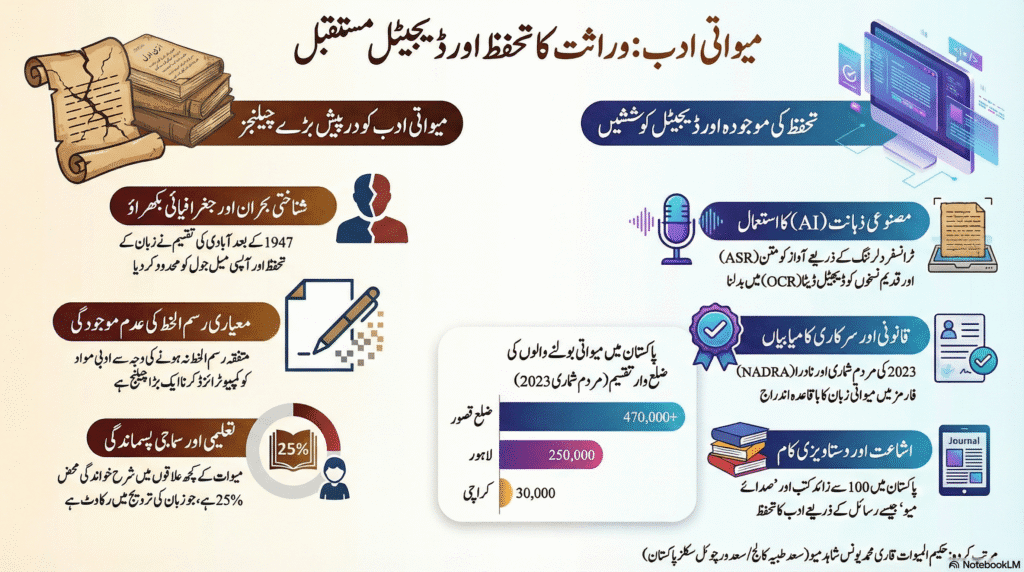
میواتی ادب کو ایک منظم اور ڈیجیٹل شکل میں محفوظ کرنے کی راہ میں کئی پیچیدہ رکاوٹیں حائل ہیں، جن کا تعلق لسانیات، سماجیات، ٹیکنالوجی اور جغرافیائی سیاست سے ہے۔
لسانی اور تعلیمی رکاوٹیں
سب سے بڑا چیلنج میواتی زبان کے لیے ایک متفقہ اور معیاری رسم الخط کی عدم موجودگی ہے۔ اگرچہ تحریری طور پر اردو یا دیوناگری کا استعمال کیا جاتا ہے، لیکن املا میں کوئی یکسانیت نہیں ہے، جس کی وجہ سے کمپیوٹر پر مبنی لسانی تجزیہ (Computational Analysis) کرنا انتہائی مشکل ہو جاتا ہے 2۔ مزید برآں، میوات کے علاقوں میں شرح خواندگی کا کم ہونا، خاص طور پر راجستھان کے کچھ حصوں میں صرف 25 فیصد، ادب کی ترویج میں بڑی رکاوٹ ہے 2۔ اساتذہ کی جانب سے کلاس روم میں میواتی زبان کے استعمال کی حوصلہ شکنی اور اسے ہندی کے مقابلے میں کم تر سمجھنے کا رویہ زبان کو مزید پسماندگی کی طرف دھکیل رہا ہے 9۔
ٹیکنالوجی اور ڈیجیٹل وسائل کی کمی
جدید دور میں کسی زبان کی بقا کا دارومدار اس کے ڈیجیٹل وسائل پر ہے۔ میواتی کو تکنیکی زبان میں ایک “کم وسائل والی زبان” (Low-Resource Language) کہا جاتا ہے 10۔ اس کے پاس نہ تو ڈیجیٹل لغات ہیں، نہ ہی کوئی ٹیگ شدہ کارپس (Annotated Corpora) دستیاب ہے۔ یہی وجہ ہے کہ یہ زبان گوگل ٹرانسلیٹ یا اسپیچ ٹو ٹیکسٹ جیسی سہولیات سے محروم ہے، جس کی وجہ سے نوجوان نسل اپنی مادری زبان کو ڈیجیٹل دنیا میں استعمال کرنے سے قاصر ہے 10۔
جغرافیائی-سیاسی تقسیم
1947 کی تقسیم نے میواتی ادب کو بھی دو حصوں میں بانٹ دیا ہے۔ ہندوستان میں قدیم زبانی روایات اور صوتی ریکارڈنگز کا بڑا ذخیرہ موجود ہے، جیسے روپاین سنستھان جودھپور کے آرکائیوز 7۔ دوسری طرف، پاکستان میں میواتی زبان کو قومی شناخت دلوانے اور تحریری ادب پیدا کرنے پر زیادہ کام ہو رہا ہے 2۔ ان دونوں خطوں کے محققین کے درمیان تعاون کی کمی کی وجہ سے ایک ادھوری تصویر سامنے آتی ہے۔ جب تک صوتی ذخائر اور تحریری مواد کو یکجا نہیں کیا جاتا، میواتی ادب کی جامع تدوین ممکن نہیں ہے۔
زبانی ورثے کی بازیافت: آٹومیٹک اسپیچ ریکگنیشن (ASR) کا اطلاق
میواتی ادب کا سب سے قیمتی حصہ صوتی شکل میں بکھرا ہوا ہے۔ اسے متن میں تبدیل کرنے کے لیے مصنوعی ذہانت کی شاخ ‘آٹومیٹک اسپیچ ریکگنیشن’ (ASR) کا استعمال ناگزیر ہے۔
ٹرانسفر لرننگ اور معاون زبان کی حکمت عملی
چونکہ میواتی کے لیے تربیت یافتہ ڈیٹا سیٹ موجود نہیں ہے، اس لیے “ٹرانسفر لرننگ” (Transfer Learning) کی تکنیک استعمال کی جائے گی۔ اس میں پہلے سے موجود طاقتور کثیر لسانی ماڈلز، جیسے AI4Bharat کے تیار کردہ IndicWav2Vec اور IndicWhisper، کو میواتی کے لیے ڈھالا جا سکتا ہے 14۔ میواتی کے لیے ہندی اور اردو بہترین “معاون زبانیں” (Donor Languages) ثابت ہو سکتی ہیں کیونکہ ان میں صوتیاتی مماثلت بہت زیادہ ہے 16۔
| ASR ماڈل | خصوصیات و افادیت | میواتی کے لیے موزونیت |
| IndicWav2Vec | خود نگرانہ (Self-supervised) ماڈل، 40 زبانوں پر تربیت یافتہ 15 | ابتدائی صوتی خصوصیات اخذ کرنے کے لیے بہترین |
| IndicWhisper | ٹرانسفارمر آرکیٹیکچر، شور والے ماحول میں بہتر کارکردگی 14 | لوک گیتوں کی ریکارڈنگز کے لیے سب سے موزوں |
| IndicConformer | کم پیرامیٹرز والا ماڈل، ریئل ٹائم اسپیچ ٹو ٹیکسٹ 14 | موبائل ایپلیکیشنز کے لیے مناسب |
نفاذ کا پائپ لائن (Implementation Pipeline)
- ڈیٹا کا حصول: روپاین سنستھان اور یوٹیوب جیسے پلیٹ فارمز سے میواتی صوتی مواد جمع کرنا 7۔
- پری پروسیسنگ: آڈیو کو 16kHz پر ری سیمپل کرنا اور شور (Noise) کو ختم کرنا 21۔
- بوٹ اسٹریپنگ: موجودہ اردو/ہندی ماڈلز کے ذریعے ابتدائی خودکار ٹرانسکرپشن تیار کرنا۔
- انسانی مداخلت (HITL): میواتی ماہرین کے ذریعے مشین سے تیار کردہ متن کی تصحیح کروا کے ایک “گولڈ اسٹینڈرڈ” کارپس بنانا 14۔
- فائن ٹیوننگ: اس اعلیٰ معیار کے ڈیٹا کے ذریعے ماڈل کو میواتی کے مخصوص لہجوں کے لیے دوبارہ تربیت دینا 16۔
تحریری ورثے کی ڈیجیٹلائزیشن: آپٹیکل کریکٹر ریکگنیشن (OCR)
پاکستان میں میواتی ادب کا ایک بڑا حصہ اردو (نستعلیق) رسم الخط میں شائع ہو چکا ہے۔ نستعلیق رسم الخط اپنی جڑی ہوئی نوعیت اور پیچیدہ اشکال کی وجہ سے OCR کے لیے ایک بڑا چیلنج ہے 6۔
نستعلیق OCR کی پیچیدگیاں
نستعلیق میں حروف اپنی پوزیشن کے لحاظ سے شکلیں بدلتے ہیں اور متعدد مرکب حروف (Ligatures) بناتے ہیں 6۔ Tesseract جیسے روایتی ٹولز اس رسم الخط پر ناکام ہو جاتے ہیں۔ لہٰذا میواتی کے لیے جدید ڈیپ لرننگ ماڈلز جیسے UTRNet اور PARSeq کا استعمال ضروری ہے 23۔
| OCR ٹیکنالوجی | طریقہ کار | کارکردگی (Accuracy) |
| UTRNet | ہائبرڈ CNN-RNN ماڈل، نستعلیق کے لیے مخصوص 22 | 92.97% (پرنٹ شدہ اردو پر) |
| PARSeq | ٹرانسفارمر اور اٹینشن میکانزم، سیاق و سباق سے آگاہ 24 | CER 0.178 (اعلیٰ درستگی) |
| Gemini-2.5-Pro | کثیر موڈل LLM، کم معیار کی تصاویر پر بھی موثر 13 | جدید ترین اور لچکدار |
میواتی کے لیے ایک مخصوص OCR ڈیٹا سیٹ بنانا ہوگا جس میں پاکستانی میواتی مطبوعات کے فونٹس اور کاغذ کی کوالٹی کی عکاسی ہو 23۔ اس کے لیے “پاکستان میو اتحاد” جیسی تنظیموں کا تعاون حاصل کرنا ہوگا تاکہ ان کی شائع کردہ 100 سے زائد کتب کو ڈیجیٹائز کیا جا سکے 2۔
متن کا تجزیہ اور تدوین: NLP کا کردار
جب مواد ڈیجیٹل متن کی شکل اختیار کر لے، تو نیچرل لینگویج پروسیسنگ (NLP) کے ٹولز اس کی تدوین اور تجزیے میں مدد فراہم کرتے ہیں۔
لسانی معیاری کاری اور خودکار لغت سازی
NLP الگورتھم میواتی املا کے تمام تغیرات (Variants) کا تجزیہ کر کے ایک باخبر معیار وضع کرنے میں مدد دے سکتے ہیں۔ اس کے ذریعے میواتی-اردو-انگریزی لغت کی تیاری کا عمل تیز ہو جائے گا، جو کہ میواتی زبان کی تعلیمی بقا کے لیے ناگزیر ہے 26۔
سمنٹک سرچ اور نالج گراف
ایک ذہین ڈیجیٹل لائبریری کی تعمیر کے لیے “سمنٹک سرچ” (Semantic Search) کا استعمال کیا جائے گا۔ اس کے لیے تمام متون کے ویکٹر ایمبیڈنگز (Vector Embeddings) تیار کر کے Pinecone یا FAISS جیسے ڈیٹا بیس میں محفوظ کیے جائیں گے 28۔ اس سے محققین الفاظ کے بجائے تصورات کی بنیاد پر تلاش کر سکیں گے، مثلاً “مویشیوں کی اہمیت سے متعلق کہاوتیں” 28۔ مزید برآں، ایک نالج گراف بنایا جائے گا جو ادیبوں، تاریخی شخصیات (جیسے حسن خان میواتی) اور ادبی کاموں کو آپس میں جوڑے گا 4۔
پاکستان میں میواتی زبان کی تحریک اور 2023 کی مردم شماری
پاکستان میں میواتی زبان کے تحفظ کی کوششیں اب ایک نئی منزل پر پہنچ چکی ہیں۔ 2023 کی ڈیجیٹل مردم شماری میں میواتی کو ایک الگ زبان کے طور پر شامل کرنا ایک تاریخی سنگِ میل ہے 5۔ اس کامیابی کا سہرا “پاکستان میو اتحاد” جیسی تنظیموں کے سر جاتا ہے جنہوں نے طویل جدوجہد کے بعد قومی سطح پر اس زبان کو تسلیم کروایا 2۔
مردم شماری کے اعداد و شمار اور ان کے اثرات
2023 کی مردم شماری کے مطابق پاکستان میں میواتی بولنے والوں کی تعداد دس لاکھ سے زائد ہے، جو کہ زیادہ تر پنجاب کے اضلاع قصور، لاہور، سیالکوٹ اور ملتان میں آباد ہیں 2۔ تاہم، ماہرین کا خیال ہے کہ اصل تعداد اس سے کہیں زیادہ ہے کیونکہ کئی افراد سماجی دباؤ کی وجہ سے اپنی مادری زبان چھپاتے ہیں 2۔ اس مردم شماری نے میواتی ادب کی تدوین کے لیے ایک ٹھوس بنیاد فراہم کی ہے، کیونکہ اب یہ زبان سرکاری طور پر تسلیم شدہ ہے، جس سے اس کے لیے فنڈنگ اور تعلیمی وسائل کا حصول آسان ہو جائے گا 5۔
| مردم شماری 2023 (پاکستان) | تفصیلات |
| میواتی بولنے والوں کی تعداد | 1,094,219 2 |
| سب سے بڑی آبادی والا ضلع | قصور (12% آبادی میواتی بولتی ہے) 2 |
| دیگر اہم شہر | لاہور (250,000)، سیالکوٹ، ملتان، کراچی 2 |
| زبان کا درجہ | قومی سطح پر تسلیم شدہ 14 زبانوں میں شامل 31 |
اخلاقی فریم ورک اور کمیونٹی کی ملکیت
ڈیجیٹل ہیومن ٹیز کے کسی بھی منصوبے میں اخلاقی پہلو سب سے اہم ہیں۔ میواتی ادب کے تحفظ میں “ڈیجیٹل استعمار” (Digital Colonialism) کے خطرات سے بچنا ضروری ہے، جہاں ڈیٹا تو حاصل کر لیا جاتا ہے لیکن اس کا فائدہ مقامی کمیونٹی کو نہیں پہنچتا 32۔
ڈیٹا کی خودمختاری اور CARE اصول
میواتی ڈیجیٹل آرکائیو کو درج ذیل بین الاقوامی اصولوں کے تحت چلایا جانا چاہیے:
- اجتماعی فائدہ (Collective Benefit): اس منصوبے کا مقصد میو برادری کی سماجی اور تعلیمی بہتری ہونا چاہیے 32۔
- اختیار (Authority to Control): ڈیٹا کی ملکیت اور اس کے استعمال کا حتمی اختیار میو برادری کی نمائندہ تنظیموں کے پاس ہونا چاہیے 32۔
- اخلاقیات (Ethics): لوک فنکاروں کے حقوق کا تحفظ اور ان کے فن کا اعتراف لازمی ہے 32۔
یونیسکو کے “مقامی زبانوں کے عالمی عشرے” (2022-2032) کے اہداف کے مطابق، میواتی زبان کو ڈیجیٹل طور پر بااختیار بنانا ایک انسانی حقوق کا مسئلہ ہے 10۔
جامع روڈ میپ اور سفارشات
میواتی ادب کی تدوینِ نو کے لیے درج ذیل مرحلہ وار سفارشات پیش کی جاتی ہیں:
- سرحد پار ڈیجیٹل تعاون: ہندوستان کے صوتی آرکائیوز اور پاکستان کے تحریری مواد کو یکجا کرنے کے لیے ایک مشترکہ ڈیجیٹل پلیٹ فارم بنایا جائے 2۔
- گولڈ اسٹینڈرڈ کارپس کی تیاری: ماہرینِ لسانیات اور AI ڈویلپرز پر مشتمل ایک ٹیم بنائی جائے جو میواتی کے لیے اعلیٰ معیار کا تربیتی ڈیٹا تیار کرے 14۔
- تعلیمی نصاب میں شمولیت: مردم شماری کے نتائج کو بنیاد بنا کر ان علاقوں میں جہاں میواتی اکثریت ہے، اسے پرائمری تعلیم کا حصہ بنایا جائے تاکہ نئی نسل اپنی زبان سے جڑی رہے 9۔
- ٹیکنالوجی پارٹنرشپ: AI4Bharat اور دیگر تحقیقی اداروں کے ساتھ مل کر میواتی کے لیے مخصوص اسپیچ اور OCR ماڈلز (MewatiAI) تیار کیے جائیں 19۔
یہ منصوبہ محض ایک تکنیکی مشق نہیں ہے، بلکہ یہ میوات کی عظیم تہذیبی تاریخ کی بحالی اور اسے آنے والی نسلوں کے لیے محفوظ کرنے کا ایک مقدس فریضہ ہے۔ مصنوعی ذہانت اور ڈیجیٹل ٹیکنالوجی کے درست استعمال سے ہم اس ادبی روایت کو وہ مقام دلا سکتے ہیں جو وقت کی گرد میں اوجھل ہو چکا تھا 10۔ میواتی ورثے کی ڈیجیٹل بحالی جنوبی ایشیا کی دیگر کم وسائل والی زبانوں کے لیے بھی ایک مشعلِ راہ ثابت ہو سکتی ہے 27۔
Works cited
- Language, literature, and dialects – Course for RPSC RAS Preparation – – EduRev, accessed on March 2, 2026, https://edurev.in/t/466958/Language–literature–and-dialects
- How did Mewati get the status of separate language in Pakistan?, accessed on March 2, 2026, https://loksujag.com/story/How-Did-Mewati-Gain-Language-Status-76-Years-After-Migration-eng
- Pandun ka Kada: A Fascinating Tradition in Fraught Times – Sahapedia, accessed on March 2, 2026, http://www.sahapedia.org/pandun-ka-kada-fascinating-tradition-fraught-times
- Mewat (Folklore Memory History) – Occult-N-Things, accessed on March 2, 2026, https://occultnthings.com/ar/products/mewat-folklore-memory-history-nag065
- 7th Population & Housing Census 2023 – Pakistan Bureau of Statistics, accessed on March 2, 2026, https://www.pbs.gov.pk/wp-content/uploads/2020/07/National-Census-Report-2023-2.pdf
- Offline Urdu OCR using Ligature based Segmentation for Nastaliq Script – Semantic Scholar, accessed on March 2, 2026, https://pdfs.semanticscholar.org/9d70/066752a8ebbcb3615bc9c8253c5f82c5d211.pdf
- Recordings of Hereditary Musicians of Western Rajasthan, accessed on March 2, 2026, https://meap.library.ucla.edu/projects/rupayan-sansthan-india/
- Epics of Rajasthan – Sahapedia, accessed on March 2, 2026, https://www.sahapedia.org/sites/default/files/Epics%20of%20Rajasthan%20-%20Komal%20Kothari.pdf
- Hello Indigenous | UNESCO, accessed on March 2, 2026, https://www.unesco.org/en/articles/hello-indigenous
- Digital preservation of Indigenous languages: At the intersection of technology and culture, accessed on March 2, 2026, https://www.unesco.org/en/articles/digital-preservation-indigenous-languages-intersection-technology-and-culture
- Protecting and Promoting Cultural and Linguistic Diversity in the Digital Environment – UNESCO, accessed on March 2, 2026, https://www.unesco.org/en/articles/protecting-and-promoting-cultural-and-linguistic-diversity-digital-environment
- UNESCO Launches Global Roadmap on Multilingualism in the Digital Era, accessed on March 2, 2026, https://www.unesco.org/en/articles/unesco-launches-global-roadmap-multilingualism-digital-era
- Rupayan Sansthan | Endangered Archives Programme, accessed on March 2, 2026, https://eap.bl.uk/collection/EAP1153-1
- Automatic Speech Recognition – AI4Bharat, accessed on March 2, 2026, https://ai4bharat.iitm.ac.in/areas/asr
- IndicWav2Vec – AI4Bharat, accessed on March 2, 2026, https://ai4bharat.iitm.ac.in/areas/model/ASR/IndicWav2Vec
- IndicWav2Vec: Robust ASR for Indic Languages – Emergent Mind, accessed on March 2, 2026, https://www.emergentmind.com/topics/indicwav2vec
- AI4Bharat – Bengali IndicWav2Vec Speech Model – AIKosh, accessed on March 2, 2026, https://aikosh.indiaai.gov.in/home/models/details/ai4bharat_indicwav2vec_speech_model_for_bengali.html
- IndicWhisper – AI4Bharat, accessed on March 2, 2026, https://ai4bharat.iitm.ac.in/areas/model/ASR/IndicWhisper
- AI4Bharat Models, accessed on March 2, 2026, https://models.ai4bharat.org/
- Arna Jharna Archive, accessed on March 2, 2026, https://arnajharna.org.in/the-archive/
- ASR for Low Resource and Multilingual Noisy Code-Mixed Speech – ISCA Archive, accessed on March 2, 2026, https://www.isca-archive.org/interspeech_2023/verma23_interspeech.pdf
- From Press to Pixels: Evolving Urdu Text Recognition – arXiv, accessed on March 2, 2026, https://arxiv.org/html/2505.13943v2
- UTRNet: High-Resolution Urdu Text Recognition in Printed Documents – ResearchGate, accessed on March 2, 2026, https://www.researchgate.net/publication/373222426_UTRNet_High-Resolution_Urdu_Text_Recognition_in_Printed_Documents
- Urdu Digital Text Word Optical Character Recognition Using Permuted Auto Regressive Sequence Modeling – ResearchGate, accessed on March 2, 2026, https://www.researchgate.net/publication/383460868_Urdu_Digital_Text_Word_Optical_Character_Recognition_Using_Permuted_Auto_Regressive_Sequence_Modeling
- [2408.15119] A Permuted Autoregressive Approach to Word-Level Recognition for Urdu Digital Text – arXiv, accessed on March 2, 2026, https://arxiv.org/abs/2408.15119
- Handbook on Endangered South Asian and Southeast Asian Languages – eBooks, accessed on March 2, 2026, https://content.e-bookshelf.de/media/reading/L-25470943-348961963e.pdf
- Language Digitization Initiative | Department of Economic and Social Affairs, accessed on March 2, 2026, https://sdgs.un.org/partnerships/language-digitization-initiative
- How to Use Pinecone Vector Database in your AI Projects? – ProjectPro, accessed on March 2, 2026, https://www.projectpro.io/article/pinecone-vector-database/1100
- What is Pinecone? A Beginner’s Guide to Vector Databases – IPRoyal.com, accessed on March 2, 2026, https://iproyal.com/blog/what-is-pinecone/
- Semantic Search with Vector Databases (FAISS, ChromaDB, Pinecone) – Langformers Blog, accessed on March 2, 2026, https://blog.langformers.com/semantic-search/
- 2023 Pakistani census – Wikipedia, accessed on March 2, 2026, https://en.wikipedia.org/wiki/2023_Pakistani_census
- Digital Heritage and the Global South – School of Archaeology, accessed on March 2, 2026, https://www.arch.ox.ac.uk/sites/default/files/archit/documents/media/03_abstracts.pdf
- DIGITAL PRESERVATION OF MINORITY LANGUAGES – Zenodo, accessed on March 2, 2026, https://zenodo.org/records/15524069
- AI4Bharat, accessed on March 2, 2026, https://ai4bharat.iitm.ac.in/

